
De boks.com FTP server is nu zichtbaar in deze web site:
Categorie: Tech talk
Muninn versie 4.1.2 uitgebracht

Muninn versie 4.1.2 is uitgebracht. Ten op zichte van versie 4.1.1 is dit veranderd:
- Meerdere knoppen zijn vervangen door knoppen met ikonen. Dit zorgt voor ruimtebesparing en ziet er leuker uit.
- Database queries zijn verbeterd en versneld en de layout van de lijst met gegevens is verbeterd – de kolombreedtes passen zich nu beter aan.
Muninn kan gratis en onbeperkt geprobeerd worden met een maximum van tien (10) accounts. De binary is verder volledig funktioneel. Om een meer accounts te kunnen bewaren is een licentie nodig. Deze licentie is te verkrijgen in de Kiwanda Embedded Systemen webshop.
Muninn kan worden gedownload voor Mac OS X, Windows 7 en hoger (64 bit) en FreeBSD 13 (64 bit) .
Muninn versie 4.1.1 uitgebracht
Muninn versie 4.1.1 is uitgebracht. Ten op zichte van versie 4.1.0 is dit veranderd:
- Het pad naar het databasebestand werd onder Windows niet goed aangegeven – dit is verbeterd.
- Enkele vertalingen waren niet goed ingevuld – verbeterd.e geb ruiker kan vanuit Muninn direkt naar het database bestand navigeren via de Finder (Mac) of de Explorer (Windows)
Muninn kan gratis en onbeperkt geprobeerd worden met een maximum van tien (10) accounts. De binary is verder volledig funktioneel. Om een meer accounts te kunnen bewaren is een licentie nodig. Deze licentie is te verkrijgen in de Kiwanda Embedded Systemen webshop.
Muninn kan worden gedownload voor Mac OS X, Windows 7 en hoger (64 bit) en FreeBSD 13 (64 bit) .
Muninn versie 4.1.0 uitgebracht
Muninn versie 4.1.0 is uitgebracht. Ten op zichte van versie 4.0.0 is dit veranderd:
- De mogelijkheid om selectief een item te zoeken is verbeterd. Een keuzemogleijkheid wordt geboden om te zoeken op een bepaald veld van het item, of in alle velden van het item tegelijkertijd. Op deze manier is het eenvoudiger om veel-gelijkende items toch apart te kunnen vinden.
- De database query verloopt sneller door een betere inrichting van de zoekterm.
- Enkele kleinere (layout) fouten opgelost.
De nieuwe 4.1.0 versie is vooralsnog alleen voor Mac OS X en Windows (64 bit) beschikbaar. Andere versie volgen binnenkort.
Muninn kan gratis en onbeperkt geprobeerd worden met een maximum van tien (10) accounts. De binary is verder volledig funktioneel. Om een meer accounts te kunnen bewaren is een licentie nodig. Deze licentie is te verkrijgen in de Kiwanda Embedded Systemen webshop.
Muninn kan worden gedownload voor Mac OS X, Windows 7 (64 bit), Linux (64 bit) en FreeBSD (64 bit) .
Muninn versie 4.0 uitgebracht
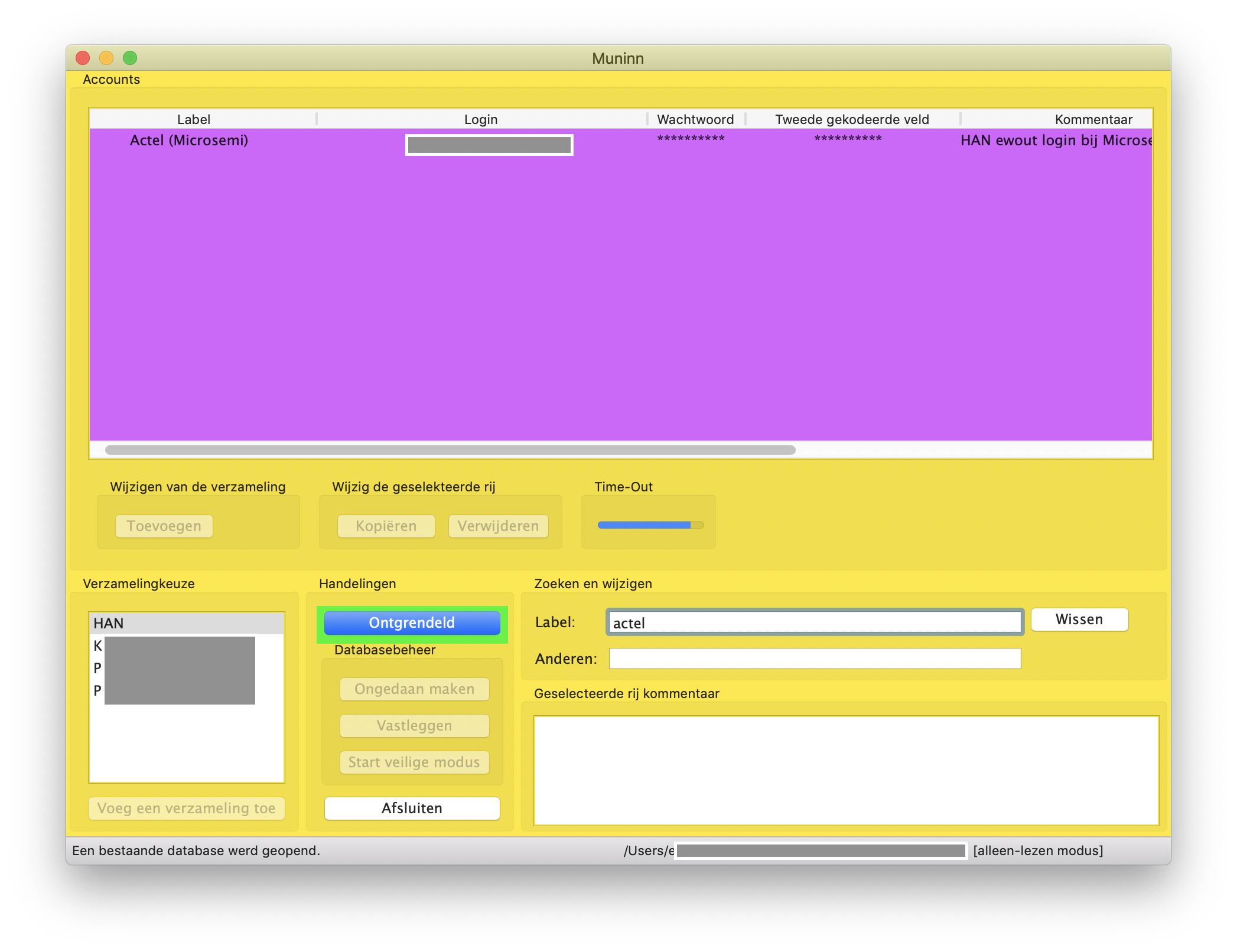
Muninn versie 4.0.0 is uitgebracht. Ten op zichte van versie 3.3.0 is dit veranderd:
- De layout van het programma is verbeterd en font en kleuren zijn verbeterd.
- De time-out timer is herschreven en werkt nu met een indikatiebalk om aan te geven hoe lang er nog over is voor dat het slot op de toegang wordt gezet.
- De database kan nu worden geopend in slechts-lezen mode. Hier door is het veilig om snel een wachtwoord te raadplegen zonder het risiko te lopen om per abuis een login te veranderen. Schakeling tussen slechts-lezen enb lezen+schrijven kan snel zonder dat het hoofdwachtwoord opnieuw hoeft te worden ingegeven.
- Diverse kleinere fouten werden opgepikt en verholpen.
- De binaire compatibiliteit met de database bestanden uit vorige releases blijft gehandhaaft. Data kan probleemloos tussen versies en platforms worden uitgewisseld.
De nieuwe 4.0 versie is vooralsnog alleen voor Mac OS X en Windows (64 bit) beschikbaar. Andere versie volgen binnenkort.
Muninn kan gratis en onbeperkt geprobeerd worden met een maximum van tien (10) accounts. De binary is verder volledig funktioneel. Om een meer accounts te kunnen bewaren is een licentie nodig. Deze licentie is te verkrijgen in de Kiwanda Embedded Systemen webshop.
Muninn kan worden gedownload voor Mac OS X, Windows 7 (64 bit), Linux (64 bit) en FreeBSD (64 bit) .
Muninn versie 3.3 uitgebracht
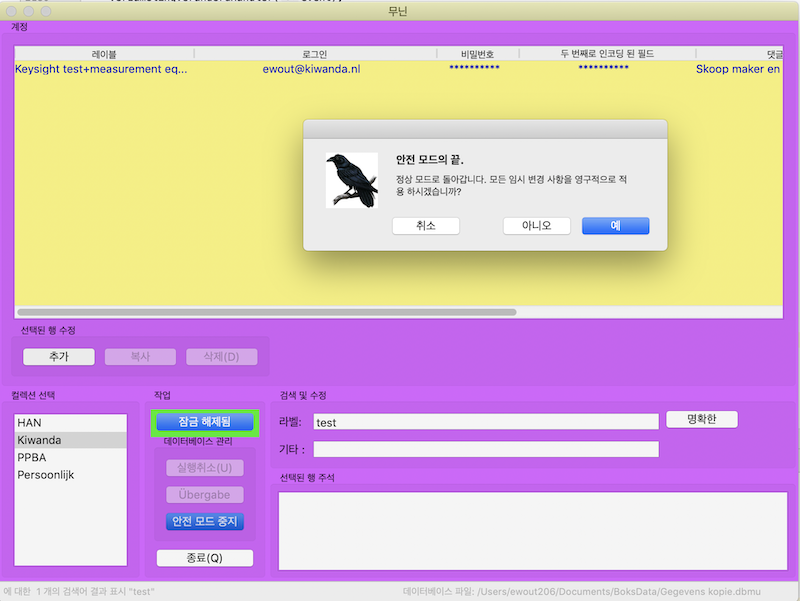
Muninn versie 3.3.0 is uitgebracht. Ten op zichte van versie 3.2.0 is dit veranderd:
- De knoppen voor toevoegen, verwijderen en dupliceren zijn verplaatst uit het zoekveld naar onderaan de lijst om hun werking duidelijker weer te geven.
- Muninn beschikt nu net als Pallas over de “Veilige modus”. Muninn kan een oneindig aantal vernanderingen aan de database bijhouden en deze terugdraaien, als de gebruiker daar toe de noodzaak ziet.
- Diverse kleine verbeteringen m.b.t de vertalingen.
Muninn kan gratis en onbeperkt geprobeerd worden met een maximum van tien (10) accounts. De binary is verder volledig funktioneel. Om een meer accounts te kunnen bewaren is een licentie nodig. Deze licentie is te verkrijgen in de Kiwanda Embedded Systemen webshop.
Muninn kan worden gedownload voor Mac OS X, Windows 7 (64 bit), Linux (64 bit) en FreeBSD (64 bit). Zie de Download rechts in de navigatierkolom.
Muninn versie 3.2 uitgebracht
Muninn versie 3.2.0 is uitgebracht. Deze versie bevat een aantal bugfixes en is geoptimaliseerd voor (zoek) snelheid. Het DB formaat en de opgeslagen account informatie worden (uiteraard) niet aangetast door deze nieuwe release.
Muninn kan gratis en onbeperkt geprobeerd worden met een maximum van tien (10) accounts. De binary is verder volledig funktioneel. Om een meer accounts te kunnen bewaren is een licentie nodig. Deze licentie is te verkrijgen in de Kiwanda Embedded Systemen webshop.
Muninn kan worden gedownload voor Mac OS X, Windows 7 (64 bit), Linux (64 bit) en FreeBSD (64 bit) :
Kalender 2.4 uitgebracht
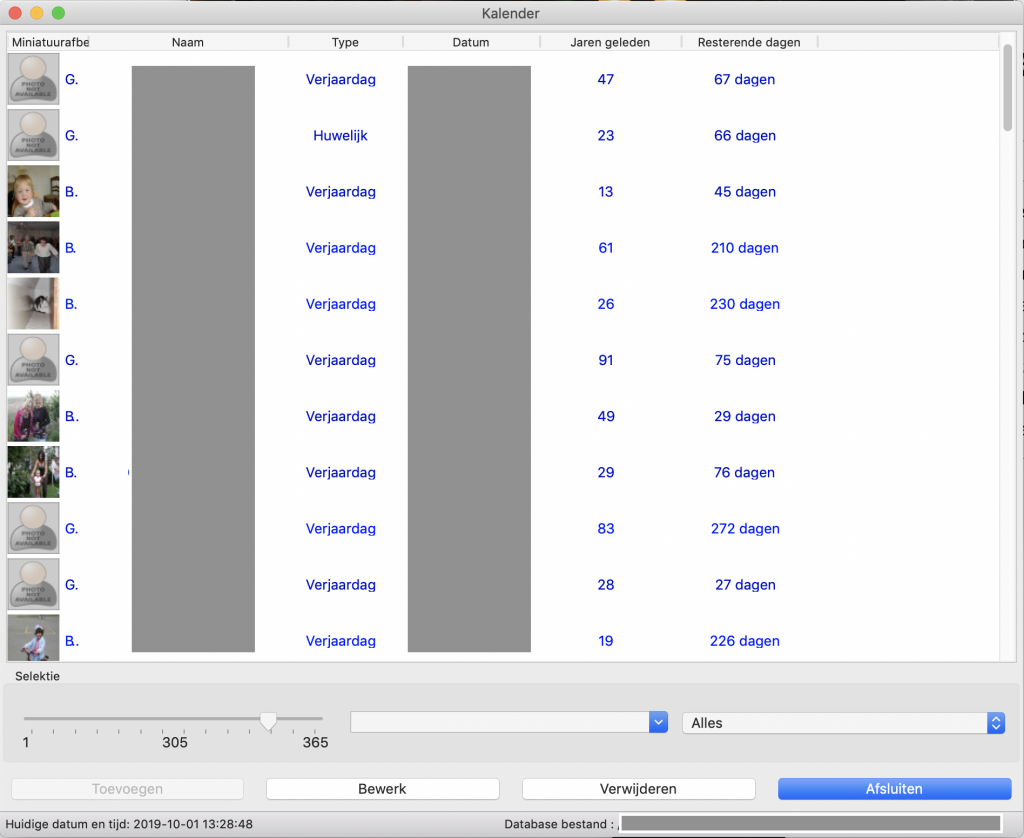
Kalender versie 2.4 is uitgebracht (zie mijn vorige post over de kalender) :
- Kalender toont nu in de lijst een miniatuur weergaven van de bijbehorende afbeelding.
- De update van de lijst is significant sneller gemaakt.
- Afbeeldingen kunnen nu op grootte worden beperkt, om de database klein te houden.
- De zoekfunktie is sterk verbeterd.
- De database kan worden gestofzuigd, om overbodige ruimte terug te geven.
De Kalender applikatie is gratis te gebruiken kan worden gedownload vanaf de FTP server.
Muninn 3.1.0 uitgebracht
Muninn, de password manager, is uitgebracht in versie 3.1.0
De nieuwe versie heeft een paar kleine aanpassingen:
- De mogelijkheid bestaat nu om een gegevenskaart te kopiëren als nieuwe database entry.
- De password generator werkt beter met het genereren van willekurige woorden op basis van getallen en speciale tekens.
- Vertalingen voor Japans en Koreaans zijn beschikbaar gemaakt.
- 日本語と韓国語の翻訳が利用可能になりました。
- 일본어와 한국어 번역이 가능합니다.
Downloads voor Muninn zijn hier beschikbaar:
Muninn diverse kleine fouten opgelost en “Keer terug” (Revert) optie aan VBS toegevoegd.
Muninn 3.0.2 heeft enkele kleinere fouten opgelost gekregen. Daarnaast is de “Revert” optie voor SVN en Git toegevoegd.
Downloads zijn te vinden via deze link.